Automated Knowledge Extraction Using Traditional NLP Techniques and Modern LLM-Driven Workflows

Abstract
This tutorial session is intended to give participants a sense of how to automate insight generation from both text and audio data using Python. This work is applicable across academic domains and industry verticals. The tutorial will involve a combination of presentations with open Q&A and hands-on exercises contained in Google Colab notebooks. Participants will learn how to extract key concepts and relationships from text and represent them visually in the form of a knowledge graph, using traditional natural language processing (NLP) techniques as well as LLM-driven workflows facilitated by the OpenAI API. The session will conclude with a focus on automating the generation of useful insights from audio data leveraging OpenAI's text generation and speech-to-text models, as demonstrated via a web app that outputs feedback from user-provided YouTube URLs and file uploads of themselves or others talking.
Topics Covered
Text Pre-Processing and Tokenization
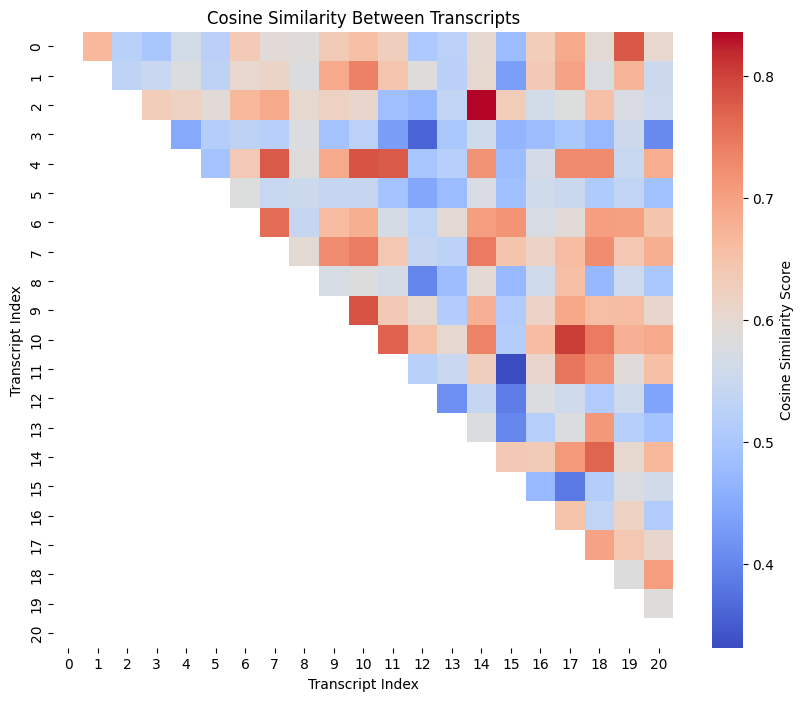
TF-IDF and Cosine Similarity
Sentiment Analysis
LLM-Driven Workflows
Retrieval-Augmented Generation
Text-to-Audio
Prompt Engineering
Highlights
- Automated Insight Generation: Participants will explore techniques to process and derive meaningful insights from text and audio data.
- Knowledge Graph Visualization: The tutorial will cover methods to visualize knowledge graphs programmatically, effectively converting extracted information from concepts and relationships into nodes and edges.
- Integration with OpenAI API: Attendees will be provided instruction on utilizing the OpenAI API to engineer LLM-driven workflows - and gain experience using traditional natural language processing (NLP) techniques - for automated insight generation.
- Interactive Instructional Materials: Instructional content will be delivered through Colab notebooks and slide decks created using reveal.js, allowing participants to follow along and engage with the material interactively within the browser.
-
Collaborative Learning Environment: The associated GitHub repo will facilitate collaboration, version control, and sharing of code and resources among participants, if they choose to install the dependencies in their own environment using either
piporconda.
This tutorial begins with the premise that we are to somehow ingest ~70 hours of YouTube videos from Enthought's YouTube channel. Beginning with the Tutorials | SciPy 2022 YouTube playlist, we are driven to generate insights from this treasure trove of knowledge.
How are we to approach this, let alone efficiently? There's only one way to find out!
Prerequisite Skills and Knowledge
- Proficiency in Python: Participants should have a solid understanding of Python programming fundamentals, including data structures, functions, loops, etc.
- Familiarity with Natural Language Processing (NLP): A basic understanding of NLP concepts, including text preprocessing and tokenization, will be beneficial but isn't required.
-
Experience with Data Visualization: Prior exposure to data visualization libraries (e.g.,
matplotlib,seaborn, etc.) will be helpful but isn't required. - Comfort with Colab Notebooks and GitHub: Participants should be familiar with working in Colab or Jupyter notebooks and navigating GitHub repositories for accessing and running code and instructional materials.
Expected Learning Outcomes
- Develop proficiency in automating insight generation from text data using Python and the OpenAI API.
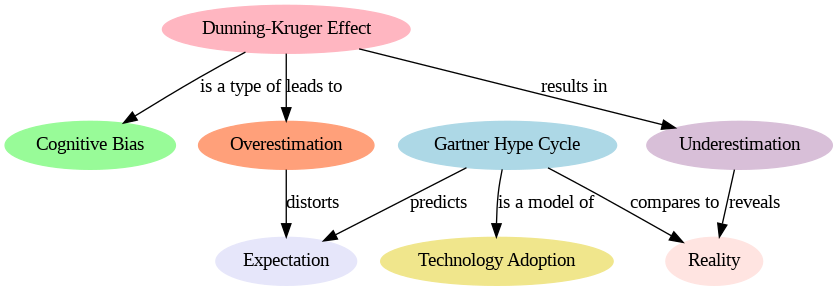
- Gain insights into techniques for extracting key concepts and relationships from text and representing them visually in the form of a knowledge graph.
- Build intuition around engineering multimodal data pipelines using traditional NLP-based techniques and modern LLM-based workflows.
Overview
This 4-hour tutorial is designed to allow at least 50% of the time for hands-on exercises and is comprised as follows:
Instruction (30 min.)
Introduction/MotivationProblem Defintion
Data Ingestion
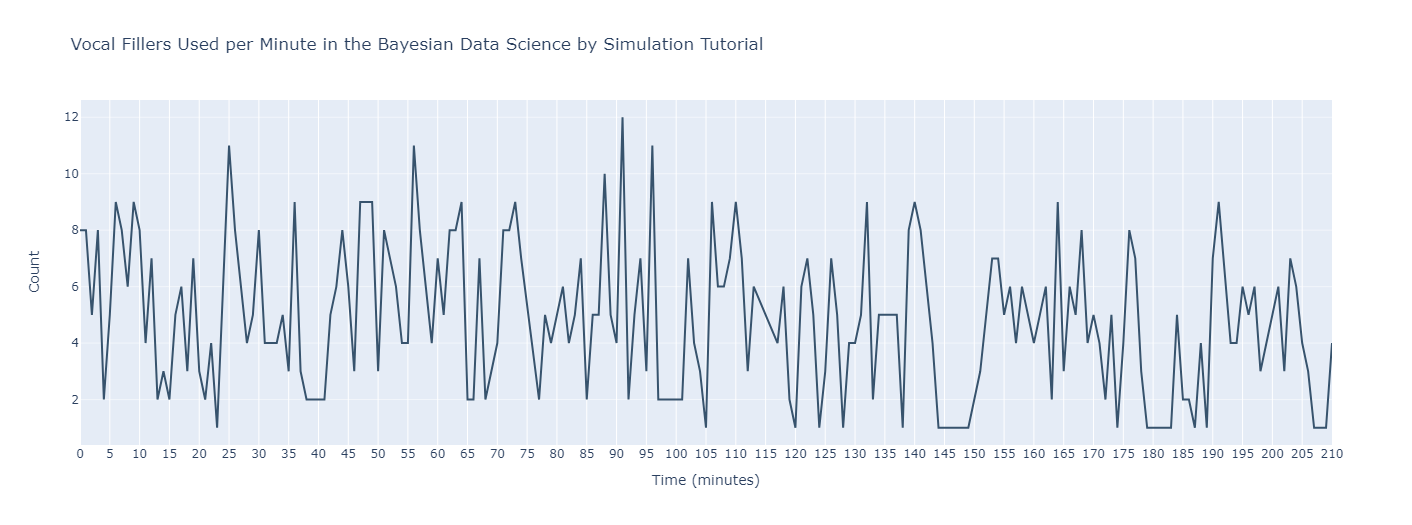
Visualizing Vocal Fillers in Speech with
Plotly
Practice (30 min.)
Tutorial Exercise: Ingesting and Exploring the DataBreak (10 min.)
Instruction (30 min.)
Text Pre-Processing Workflows withNLTK
Evaluating Text Similarity with
Matplotlib and Seaborn
Generating a Knowledge Graph Visualization with
Graphviz and GPT-4
Practice (30 min.)
Tutorial Exercise: Building a Recommender System Using Cosine Similarity between StringsBreak (10 min.)
Instruction (30 min.)
Retrieval-Augmented Generation (RAG) Using theOpenAI API
Prompt Engineering, Chunking Strategies, and Open-Source Alternatives
Tokens, Embeddings, and Cost Estimation
Practice (30 min.)
Tutorial Exercise: Building a Recommender System Using Cosine Similarity between Vector EmbeddingsBreak (10 min.)
Instruction (20 min.)
Text-to-Speech (and Vice Versa) with OpenAI and Open SourceApp Demo: Towards Multimodal Agents